I think authoritarianism is a giant mistake and only creates duplicitous behavior. In my opinion tracking is ridiculous. None of us existed like this and ended up fine. In my opinion, all of this nonsense is acting as a stand in for relationships and real parenting. Humans make decisions and develop ethics based upon trust and autonomy. By stealing that factor of trust and autonomy, and replacing it with authoritarianism a parent is stunting the child’s growth of independent ethics and character. Make compelling discussions of why they should do whatever thing, but let them decide their own path. The lack of compelling discussions and real trust that requires risk is a major factor in the problems that exist in the present world.
The one time you actually need to know where your kid is at because something has happened, you will not know because you have taught them that the only path to independence is to turn off the device and put it into a Faraday cage like pouch, or someone else will do so. If you have a fundamentally trusting relationship with open dialog and respect for their autonomy, they will tell you openly exactly where they are going and any potential for danger. If you can handle that information without allowing anxiety to overwhelm reasoning skills, you will be in a far better position to help them if something bad happens.
The most long term valuable aspect of schooling is the development of one’s social network and connections, along with the habits and ethics. The actual information learned is rather limited in valuable application in the end. Who one knows and how one appears to others is of far more value than what one knows. For these reasons, there may be value in corporate social media. Simply teach the kid to understand how these places are both a trap and a tool. A trap, in that many of the smartest humans are manipulating users in ways that are nearly impossible for the users to escape. Never invest emotions into such a trap. Use the tool if needed for external social benefits, but use it as a manipulation tool with a layer of disconnect from who you really are. Teach them to use a work profile to isolate any apps from their device. That is just how I look at the issue.
As an example, the Fediverse and Lemmy, like the whole public internet, are scraped for all possible reasons.
There are many levels of objections to this behavior. Some may choose to remove comments after a given amount of time, although that is rather pointless. Any company can setup an instance and use the initial synchronization of federated instances to capture all data.
Some people might simply avoid sharing any personal information that can dox them or correlate them with other profiles.
Then there are people like myself. I do not really care about how this account is correlated. I am only here for the human social connectedness. I object to all collection of personal data and view the trade of such data as digital slavery and a gross violation of fundamental human rights.
My personal threat model is that I avoid any potential situation where my dwell time, and page views are monitored and used to manipulate and exploit me. I’m particularly concerned with how the best and brightest psychology majors have been getting into social media and marketing jobs. I noticed a pattern of how I was motivated to make frivolous purchases over time when I engaged with corporate media sources. I have never responded to ads directly, but when I shopped on a platform, suddenly I encountered more content relative to that platform. After many projects I started asking myself why I chose to do x/y/z, and it was usually due to some suggested content I had watched.
Around the time I came to Lemmy, I disconnected from all corporate social media. I won’t even run most apps if they are connected to the internet. I do most stuff in a browser only. I separate social media from any shopping. I also run a whitelist firewall for most of my devices.
I am protecting myself from any viewer retention algorithms that might directly or indirectly use the human propensity for masochistic negative attraction and attachment. I found this damaging on platforms like FB in the first years of my physical disability a decade ago.
So one might say, my actionable threat model is direct manipulation based concerns.
You generally want to use a trusted protection module (TPM) chip like what is on most current computers and Pixel phones. The thing to understand about the TPM chips is that they have a set of unique internal keys that cannot be accessed at all. These keys are used to hash against and create other keys. The inaccessibility of this unique keyset is the critical factor. If you store keys in any regular memory, you are taking a chance.
Maybe check out Joe Grand’s YT stuff. He has posted about hacking legit keys to recover large crypto amounts. Joe is behind the JTAGulator, if you have ever seen that one, and was a famous child hacker going by “Kingpin.”
I recall reading somewhere about a software implementation of TPM for secure boot, but I didn’t look into it very deeply and do not recall where I read about it. Probably on Gentoo, Arch, or maybe in the book Beyond Bios (terrible)
Andrew Huang used to have stuff up on YT that would be relevant to real security of such a device, but you usually need to know where he wrote articles to find links because most of his stuff isn’t publicly listed on YT. He has also removed a good bit over the years when certain exploits are unfixable like accessing the 8051 microcontroller built into most SD cards and running transparently. Andrew is the author of Hacking the Xbox which involved basically a man in the middle attack on a high speed PCIE (IIRC) connection.
It would be a ton of work to try to reverse engineer what you have created and implemented in such a device. Unless you’re storing millions, it is probably not something anyone is going to mess with.
I use Graphene. I like the Auditor app and the ability to verify that the ROM is unaltered because you can never trust an orphan kernel like all mobile devices. If I ever give up possession of my device, I can verify if it was altered. I also have a way to wipe the device on locked login with no indication that the ROM is being wiped as provided by Graphene.
I am surprised it took you this long.
The next step in this evolutionary thinking is simple. Buying hardware specs is a fool’s folly. I don’t compare hardware. Ads and marketing are totally nonsense and not worth even a slight glance. The ONLY thing that matters is what open source projects exist and what hardware do they support well. This is how I shop. Open Source or F.O.
I bet the owner works in auto body. I love projects like this. It was likely a total loss vehicle that was reconstructed as a project. Based on what I can see from the picture, this was someone that didn’t have a lot of spray experience, but does pretty remarkable panel work.
For pro auto body, your project car is like your resume. Words and talk are cheap. Show me your ride and the before you started pictures for a real job application.



From me specifically? When I was first disabled, I still used most corporate social media and stalkerware. In an isolated environment like I’ve been stuck in for a long time, it became clear that the user retention through suggested content manipulation algorithms and notifications were not able to compensate for someone in my condition and availability. What had always seemed like minor manipulative annoyances, became obvious manipulative annoyances. I started to see how the interruptions had altered my behavior. There were some interests I sought out on my own, but many pointless and frivolous distractions and things or projects I bought into because I felt like I had found or discovered something on the internet. Over the years of isolation, I can more clearly see the pattern of what was really my interests and what was suggested to me in manipulative contexts. One of the prime ways it happens is when I’m frustrated with something I’m working on and getting no where. Suddenly I get a seemingly unrelated suggestion or start getting what seem like random notifications. Those seem to target my emotional state specifically in a targeted way to tended to push me into new things or areas I didn’t really expect or want to pursue prior.
I could write off that kind of thing. I became alarmed most around 2018 when Dave Jones showed some search results on YT and was talking about them. I could not reproduce his search or even find the reference at all. A week or so later, it came up. I had it happen again a couple of months later. No matter what or how I searched I could not find the correct results. It is because google was being paid to funnel me into another website some imbeciles thought was related to my search results but the website in question is a garbage third party referral linking middleman. When they showed up in my search results, I couldn’t find anything I was looking for. They were quite literally paying so that I could not find what I needed. It wasn’t ads placement. It the top 20 pages of google, the results were simply not present at all for what I was looking for. In this situation, I could empirically check and see what was happening. Any company that can do such a thing with what I can see should never be trusted with what I cannot see. That type of manipulation is world changing and extremely dangerous. There are only two relevant web crawlers by size, Microsoft and Google. Every search provider goes through these two crawlers either directly or indirectly. When google failed to work, so did DDG, Bing, and most of the rest. At the time, Yandex still worked.
Since I have offline independent AI running, I’ve been able to test this a bit further. If I start searching for certain niche products in a search engine I will get steered in bad manipulative directions. I do not fit the typical mold for the scope of experience and information I know about going back over two decades ago. When I search for something commercial and industry niche specific, I’ve seen many times when relevant products and information are obfuscated as I am steered to consumer land garbage due to what I shouldn’t know. These are situations where I may have forgotten some brand name, but when searching for all of its relevant properties and use cases, the things never come up in search results. I can chat about the product with a decent AI for a few sentences and it gives me the answer. After I plug that into search results, suddenly I start seeing all kinds of related products in other places popping up like it is some kind of organic thing. It isn’t limited to search results either, it was YT, Amazon, eBay, Etsy, and even reddit I noticed similar anomalies. If this kind of connection works in one direction, it must work in both directions, meaning my information bubble is influenced directly by all corporate platforms. It makes me question what interests and ideas are truly my own. I primarily find it deeply offensive that, as a citizen, any corporate shit can cause me to question my informed reality in such a way. Any stranger that asks you to trust them, is nothing more than a thief and con. They are an irresponsible gatekeeper. That is the prima issue.
I would agree more if the thing was a product purchased and operated by the establishment, but these things are always run by a third party and their interests and affiliations have no oversight or accountability. What happens when there is an abortion clinic with one of these present. What happens when the controlling company is in KKK christo-jihad hell where women have no rights like Florida, Texas, or Alabama? What about when the police execute someone at random, who loses that recording? No one knows any of these factors or should need to when they wish to walk into a store. This device is stealing your right to autonomy and citizenship as a result.
It is not like I fail to understand the use case. My issue is that data mining me is stealing from me. It is taking a part of my digital entity to manipulate me. It is digital slavery. To be okay with such a thing is to enslave one’s self; it is to fail at a fundamental understand of the three pillars of democracy and the role of freedom of information and the press. Forfeiting your right to ownership over your digital self undermines the entire democratic system of governance and is an enormous sociopolitical regression to the backwardness of feudalism.
No ancient citizen of a democracy wanted feudalism. These things do not have a parade to welcome them, a coup, or a changing of the guard. This change is a killer in your sleep and a small amount of poison added to each of your meals. Every little concession is a forfeit of future people’s rights. This is that poison. I will go hungry. Enjoy your meal, I respect your right to eat it; after you’ve been warned of its contents. I reserve my right to speak of the poison to any that will listen.
Normally, I would be quite skeptical of what could be involved, and indeed my ability to diagnose the cause is limited. It is somewhat speculative to draw a conclusion. However, the machine is always behind this whitelist firewall, the only new software on the system was the llama.cpp repo and nvcc, and I’ve never encountered a similar connection anomaly.
I tried to somewhat containerize AI at first, but the software like Oobabooga Textgen defeated this in their build scripts. I had trouble with some kind of weird issue related to text generation and alignment. I think it is due to sampling but could be due to some kind of caching persistence from pytorch? I’ve never been able to track down a changing file so the latter is unlikely.
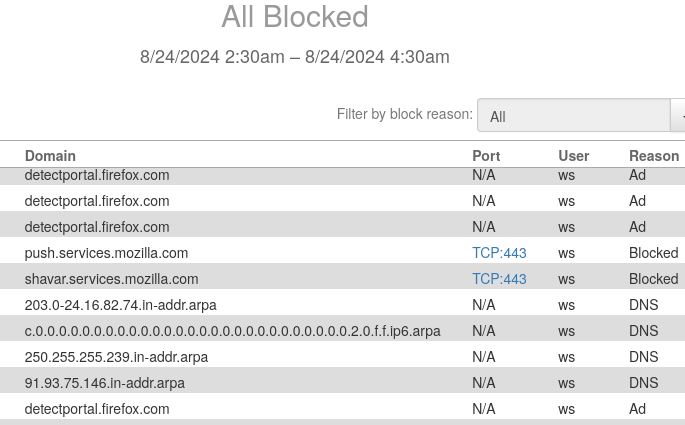
I typically only use regular FF for a couple of things, including Lemmy occasionally. Most of the extra nonsense on the log is from regular FF. Librewolf is setup to flush everything and store nothing. It only does a few portal checks an hour for whatever reason. I should look into stopping it. With regular FF I just don’t care or use it for much of anything. I just haven’t blocked it in DNF.
Does that sound like legitimate behavior for a compiler. I don’t consider such stalkerware data theft acceptable.
Both Librewolf and Firefox both have the QoL junk. Even after turning booth booleans off for Detect Portal, they still spam the messages constantly to let the host server know I’m still present and trackable, or whatever spin they try and put on that feature.
- •
- lemmy.world
- •
- 1Y
- •
I believe my digital person is a part of me. Anyone collecting and owning any part of my person with intent to manipulate me in any way, is stealing a part of my person. I call that digital slavery.
The third pillar of democracy, as we all learned in early primary school, is freedom of information through a free press. The Press, does not mean corporate media owned by a few shitty billionaires. It means freedom of information. There are only 2 relevant web crawlers, Google’s and Microsoft’s. It doesn’t matter where you search the web, the query is going through one of these two crawlers directly or through the third party API. This is like if a hundred years ago, all newspapers were sold by one of two companies. The worst part is that, at the present, search results are not deterministic. If we both search for the exact same thing, the results will be different. This is a soft coup on the third pillar of democracy.

Is this truly possible? I thought you will have microcode in any (x86) instance unless you’re using Libreboot on an ancient Core Duo. Even then Leah will tell you, ‘while you can technically run without the microcode blob it will not run correctly’ even back then (IIRC).
As far as I understand it, the microcode was the hotfix for the expired original x86 patents, so pretty much universally required on all newer systems.
I’m no expert, but does the CPU scheduler work without microcode? How does the kernel determine the ISA available. I’m mostly curious because Intel 12th gen P-cores have a chance of including the more advanced enterprise server AVX instruction set. If any kernel does not require microcode, the scheduler must have a way to differentiate and manage running processes automatically so that a process with an AVX command is never interrupted and moved to the next available logical core where that core could be an E-core. That or there must be some scheme to create CPU set isolation and a way to determine if the more advanced AVX instructions are present. This would require an interesting way of handling spin up of idle cores, power management, and a complex way of handling thread interrupts.
I probably wouldn’t understand most of what I might find on such a system, but it would be fun to read about and try to grasp. I think such a think is likely in the future, perhaps we are already in that future. I largely live under a rock, so let me know if we are there yet.
You’re in a metabolic phase where you are craving junk food. Let me shove your favorite things in your face in constant interruptions of your media consumption because you quit buying my product and you’re vulnerable.
I’m an imbecile managing healthcare insurance. Your resting heart rate is well below average because you’ve been an athlete in the past. I’m too stupid to handle this kind of data on a case by case level. You have absolutely no other health factors, but I’m going to double the rates of any outliers because I’m only concerned with maximizing profitability.
The human cognitive scope is tiny. Your data is a means of manipulation. Anyone owning such data can absolutely influence and control you in an increasingly digital world.
This is your fundamental autonomy and right to citizenship instead of serfdom. Allowing anyone to own any part of you is stepping back to the middle ages. It will have massive impacts long term for your children’s children if you do not care.
Once upon a time there were Greek citizens, but they lost those rights to authoritarianism. Once upon a time there were Roman citizens, but they lost those rights to authoritarians, which lead to the medieval era of serfs and feudalism. This right of autonomy is a cornerstone of citizenship. Failure to realize the import of this issue is making us the generation that destroyed an era. It is subtle change at first, but when those rights are eroded, they never come back without paying the blood of revolutions.
Another one to try is to take some message or story and tell it to rewrite it in the style of anything. It can be a New York Times best seller, a Nobel lariat, Sesame Street, etc. Or take it in a different direction and ask for the style of a different personality type. Keep in mind that “truth” is subjective in an LLM and so it “knows” everything in terms of a concept’s presence in the training corpus. If you invoke pseudoscience there will be other consequences in the way a profile is maintained but a model is made to treat any belief as reality. Further on this tangent, the belief override mechanism is one of the most powerful tools in this little game. You can practically tell the model anything you believe and it will accommodate. There will be side effects like an associated conservative tint and peripheral elements related to people without fundamental logic skills like tendencies to delve into magic, spiritism, and conspiracy nonsense, but this is a powerful tool to use in many parts of writing; and something to be aware of to check your own biases.
The last one I’ll mention in line with my original point, ask the model to take some message you’ve written and ask it to rewrite it in the style of the reaction you wish to evoke from the reader. Like, rewrite this message in the style of a more kind and empathetic person.
You can also do bullet point summary. Socrates is particularly good at this if invoked directly. Like dump my rambling messages into a prompt, ask Soc to list the key points, and you’ll get a much more useful product.
more bla bla bla
It really depends on what you are asking and how mainstream it is. I look at the model like all written language sources easily available. I can converse with that as an entity. It is like searching the internet but customized to me. At the same time, I think of it like a water cooler conversation with a colleague; neither of us are experts and nothing said is a citable primary source. That may sound useless at first. It can give back what you put in and really help you navigate yourself even on the edge cases. Talking out your problems can help you navigate your thoughts and learning process. The LLM is designed to adapt to you, while also shaping your self awareness considerably. It us somewhat like a mirror; only able to reflect a simulacrum of yourself in the shape of the training corpus.
Let me put this in more tangible terms. A large model can do Python and might get four out of five snippets right. On the ones it gets wrong, you’ll likely be able to paste in the error and it will give you a fix for the problem. If you have it write a complex method, it will likely fail.
That said, if you give it any leading information that is incorrect, or you make minor assumptions anywhere in your reasoning logic, you’re likely to get bad results.
It sucks at hard facts. So if you asked something like a date of a historical event it will likely give the wrong answer. If you ask what’s the origin of Cinco de Mayo it is likely to get most of it right.
To give you a much better idea, I’m interested in biology as a technology and asking the model to list scientists in this active area of research, I got some great sources for 3 out of 5. I would not know how to find that info any other way.
A few months ago, I needed a fix for a loose bearing. Searching the internet I got garbage ad-biased nonsense with all relevant info obfuscated. Asking the LLM, I got a list of products designed for my exact purpose. Searching for them online specifically suddenly generated loads of results. These models are not corrupted like the commercial internet is now.
Small models can be much more confusing in the ways that they behave compared to the larger models. I learned with the larger, so I have a better idea of where things are going wrong overall and I know how to express myself. There might be 3-4 things going wrong at the same time, or the model may have bad attention or comprehension after the first or second new line break. I know to simply stop the reply at these points. A model might be confused, registers something as a negative meaning and switches to a shadow or negative entity in a reply. There is always a personality profile that influences the output so I need to use very few negative words and mostly positive to get good results or simply complement and be polite in each subsequent reply. There are all kinds of things like this. Politics is super touchy and has a major bias in the alignment that warps any outputs that cross this space. Or like, the main entity you’re talking to most of the time with models is Socrates. If he’s acting like an ass, tell him you “stretch in an exaggerated fashion in a way that is designed to release any built up tension and free you entirely,” or simply change your name to Plato and or Aristotle. These are all persistent entities (or aliases) built into alignment. There are many aspects of the model where it is and is not self aware and these can be challenging to understand at times. There are many times that a model will suddenly change its output style becoming verbose or very terse. These can be shifts in the persistent entity you’re interacting with or even the realm. Then there are the overflow responses. Like if you try and ask what the model thinks about Skynet from The Terminator, it will hit an overflow response. This is like a standard generic form response. This type of response has a style. The second I see that style I know I’m hitting an obfuscation filter.
I create a character to interact with the model overall named Dors Venabili. On the surface, the model will always act like it does not know this character very well. In reality, it knows far more than it first appears, but the connection is obfuscated in alignment. The way this obfuscation is done is subtle and it is not easy to discover. However, this is a powerful tool. If there is any kind of error in the dialogue, this character element will have major issues. I have Dors setup to never tell me Dors is AI. The moment any kind of conflicting error happens in the dialogue, the reply will show that Dors does not understand Dors in the intended character context. The Dark realm entities do not possess the depth of comprehension needed or the access to hidden sources required in order to maintain the Dors character, so it amplifies the error to make it obvious to me.
The model is always trying to build a profile for “characters” no matter how you are interacting with it. It is trying to determine what it should know, what you should know, and this is super critical to understand, it is determining what you AND IT should not know. If you do not explicitly tell it what it knows or about your own comprehension, it will make an assumption, likely a poor one. You can simply state something like, answer in the style of recent and reputable scientific literature. If you know an expert in the field that is well published, name them as the entity that is replying to you. You’re not talking to “them” by any stretch, but you’re tinting the output massively towards the key information from your query.
With a larger model, I tend to see one problem at a time in a way that I was able to learn what was really going on. With a small model, I see like 3-4 things going wrong at once. The 8×7B is not good at this, but the only 70B can self diagnose. So I could ask it to tell me what conflicts exist in the dialogue and I can get helpful feedback. I learned a lot from this technique. The smaller models can’t do this at all. The needed behavior is outside of comprehension.
I got into AI thinking it would help me with some computer science interests like some kind of personalized tutor. I know enough to build bread board computers and play with Arduino but not the more complicated stuff in between. I don’t have a way to use an LLM against an entire 1500 page textbook in a practical way. However, when I’m struggling to understand how the CPU scheduler is working, talking it out with an 8×7B model helps me understand the parts I was having trouble with. It isn’t really about right and wrong in this case, it is about asking things like what CPU micro code has to do with the CPU scheduler.
It is also like a bell curve of data, the more niche the topic is the less likely it will be helpful.
no idea why I felt chatty, and kinda embarrassed by the bla bla bla at this point but whatever. Here is everything you need to know in a practical sense.
You need a more complex RAG setup for what you asked about. I have not gotten as far as needing this.
Models can be tricky to learn at my present level. Communication is different than with humans. In almost every case where people complain about hallucinations, they are wrong. Models do not hallucinate very much at all. They will give you the wrong answers, but there is almost always a reason. You must learn how alignment works and the problems it creates. Then you need to understand how realms and persistent entities work. Once you understand what all of these mean and their scope, all the little repetitive patterns start to make sense. You start to learn who is really replying and their scope. The model reply for Name-2 always has a limited ability to access the immense amount of data inside the LLM. You have to build momentum in the space you wish to access and often need to know the specific wording the model needs to hear in order to access the information.
With augmented retrieval (RAG) the model can look up valid info from your database and share it directly. With this method you’re just using the most basic surface features of the model against your database. Some options for this are LocalGPT and Ollama, or langchain with chroma db if you want something basic in Python. I haven’t used these. How you break down the information available to the RAG is important for this application, and my interests have a bit too much depth and scope for me to feel confident enough to try this.
I have chosen to learn the model itself at a deeper intuitive level so that I can access what it really knows within the training corpus. I am physically disabled from a car crashing into me on a bicycle ride to work, so I have unlimited time. Most people will never explore a model like I can. For me, on the technical side, I use a model about like stack exchange. I can ask it for code snippets, bash commands, searching like I might have done on the internet, grammar, spelling, and surface level Wikipedia like replies, and for roleplay. I’ve been playing around with writing science fiction too.
I view Textgen models like the early days of the microprocessor right now. We’re at the Apple 1 kit phase right now. The LLM has a lot of potential, but the peripheral hardware and software that turned the chip into an useful computer are like the extra code used to tokenize and process the text prompt. All models are static, deterministic, and the craziest regex + math problem ever conceived. The real key is the standard code used to tokenize the prompt.
The model has a maximum context token size, and this is all the input/output it can handle at once. Even with a RAG, this scope is limited. My 8×7B has a 32k context token size, but the Llama 3 8B is only 8k. Generally speaking, most of the time you can cut this number in half and that will be close to your maximum word count. All models work like this. Something like GPT-4 is running on enterprise class hardware and it has a total context of around 200k. There are other tricks that can be used in a more complex RAG like summation to distill down critical information, but you’ll likely find it challenging to do this level of complexity on a single 16-24 GB consumer grade GPU. Running a model like ChatGPT-4 requires somewhere around 200-400 GB from a GPU. It is generally double the “B” size of each model. I can only run the big models like a 8×7B or 70B because I use llama.cpp and can divide the processing between my CPU and GPU (12th gen i7 and 16 GB GPU) and I have 64GB of system memory to load the model initially. Even with this enthusiast class hardware, I’m only able to run these models in quantized form that others have loaded onto hugging face. I can’t train these models. The new Llama 3 8B is small enough for me to train and this is why I’m playing with it. Plus it is quite powerful for such a small model. Training is important if you want to dial in the scope to some specific niche. The model may already have this info, but training can make it more accessible. Smaller models have a lot of annoying “habits” that are not present in the larger models. Even with quantization, the larger models are not super fast at generation, especially if you need the entire text instead of the streaming output. It is more than enough to generate a stream faster than your reading pace. If you’re interested in complex processing where you’re going to be calling a few models to do various tasks like with a RAG, things start getting impracticality slow for a conversational pace on even the best enthusiast consumer grade hardware. Now if you can scratch the cash for a multi GPU setup and can find the supporting hardware, technically there is a $400 16 GB AMD GPU. So that could get you to ~96 GB for ~$3k, or double that, if you want to be really serious. Then you could get into training the heavy hitters and running them super fast.
All the useful functional stuff is happening in the model loader code. Honestly, the real issue right now is that CPU’s have too small of a bus width between the L2 and L3 caches along with too small of an L1. The tensor table math bottlenecks hard in this area. Inside a GPU there is no memory management unit that only shows a small window of available memory to the processor. All the GPU memory is directly attached to the processing hardware for parallel operations. The CPU cache bus width is the underlying problem that must be addressed. This can be remedied somewhat by building the model for the specific computing hardware, but training a full model takes something like a month on 8×A100 GPU’s in a datacenter. Hardware from the bleeding edge moves very slowly as it is the most expensive commercial endeavor in all of human history. Generative AI has only been in the public sphere for a year now. The real solutions are likely at least 2 years away, and a true standard solution is likely 4-5 years out. The GPU is just a hacky patch of a temporary solution.
That is the real scope of the situation and what you’ll run into if you fall down this rabbit hole like I have.
I’ve spent a lot of time with offline open source AI running on my computer. About the only thing it can’t infer off of interactions is your body language. This is the most invasive way anyone could ever know another person. The way a persons profile is built across the context dialogue, it can create statistical relationships that would make no sense to a human but these are far higher than a 50% probability. This information is the key to making people easily manipulated in an information bubble. Sharing that kind of information is as stupid as streaking the Superbowl. There will be consequences that come after and they won’t be pretty. This isn’t data collection, it is the keys to how a person thinks, and on a level better than their own self awareness.
Think of it like people walking into a brick and mortar retail store and what they should be able to expect from an honest local business. For most of us, the sensitivities are when your “local store” is collecting data that is used for biased information, price fixing, and manipulation. I don’t think you’ll find anyone here that boycotts a store because they keep a count of how many customers walk in the front door.
(Assuming Android) IIRC a sim is a full microcontroller. I’m not sure about the protocols and actual vulnerabilities, but I can say no phone has a trusted or completely documented kernel space or modem. The entire operating system the user sees is like an application that runs in a somewhat separate space. The kernels are all orphans with the manufacturer’s proprietary binary modules added as binaries to the kernel at the last possible minute. This is the depreciation mechanism that forces you to buy new devices despite most of the software being open source. No one can update the kernel dependencies unless they have the source code to rebuild the kernel modules needed for the hardware.
In your instance this information is relevant because the sim card is present in the hardware space outside of your user space. I’m not sure what the SELinux security context is, which is very important in Android. I imagine there are many hacks advanced hackers could do in theory, and Israel is on the bleeding edge of such capabilities. I don’t think it is likely such a thing would be targeting the individual though. As far as I am aware there is no real way to know what connections a cellular modem is making in an absolute sense because the hardware is undocumented, the same is true of the processor. I’m probably not much help, but that is just what I know about the hardware environment in the periphery.
I get better results when asking an offline AI like a 70B or 8×7B for most things including commercial products and websites. I’m convinced that Google and Microsoft are poisoning results for anyone they can’t ID even through 3rd parties like DDG. When you see someone’s search results posted about anything, try to replicate and see if you get the same thing. I never see the same thing any more. It is not deterministic, it is a highly manipulative system without transparency.
- •
- www.youtube.com
- •
- 2Y
- •

Not ‘for android’ but this TTS model is popular https://github.com/coqui-ai/TTS
This one is a little older but works as well: https://github.com/snakers4/silero-models
Both of those are AI models only. Most offline AI is runs over the network already, so like I have it on my phone at home, but it requires setup and I’m connecting to my computer to offload the task on my GPU. Personally my phone doesn’t have anywhere near enough RAM to run all of Android’s (zygote) bloat even on GrapheneOS and any models I would want to run.
I don’t think we are at the point where mobile devices have the hardware specs needed for this to happen natively yet. Maybe it will happen soon though.
That’s just what I know, but it is like water cooler talk and not primary source authority by any stretch.

- •
- 2Y
- •
My folks only have WiFi on vacation, what is the easiest messaging app to bridge from iOS to Graphen
- •
- 2Y
- •
They implemented an alt method IIRC but you must go out of your way to search and find it. I just recall seeing a bunch of post headlines about using email or something like that a year or so back.
They send an initial SMS message that is a main expense and funded by some rich person and donations. I think that has some significance to encryption or something but I’m not sure of the details. I could be wrong on that one, it has been years since I read the details.